
Without the ability to sense, reason, and act appropriately, robots and autonomous systems are nothing more than a collection of expensive parts. The inability to leverage machine intelligence to deliver autonomous systems with these capabilities is arguably the most substantial hindrance to adoption.
There are several reasons for the modest impact of AI within robotics. Firstly, solutions are often tailored to one specific application domain or problem, leading to brittle implementations that fail to generalize. Second, it is common for techniques and components to be stitched together to provide a tailor made solution that is compatible or optimized for the sensor suite on a particular robot and the environment it will operate in. Custom solutions are expensive to engineer and are not amenable to adaptation when the task configuration changes.
To alleviate these problems and to accelerate the development of intelligent capabilities in robots, we present GRID: the General Robot Intelligence Development platform. GRID is composed of foundation models, large language models, and is designed for prototyping intelligent and safe robotic capabilities.
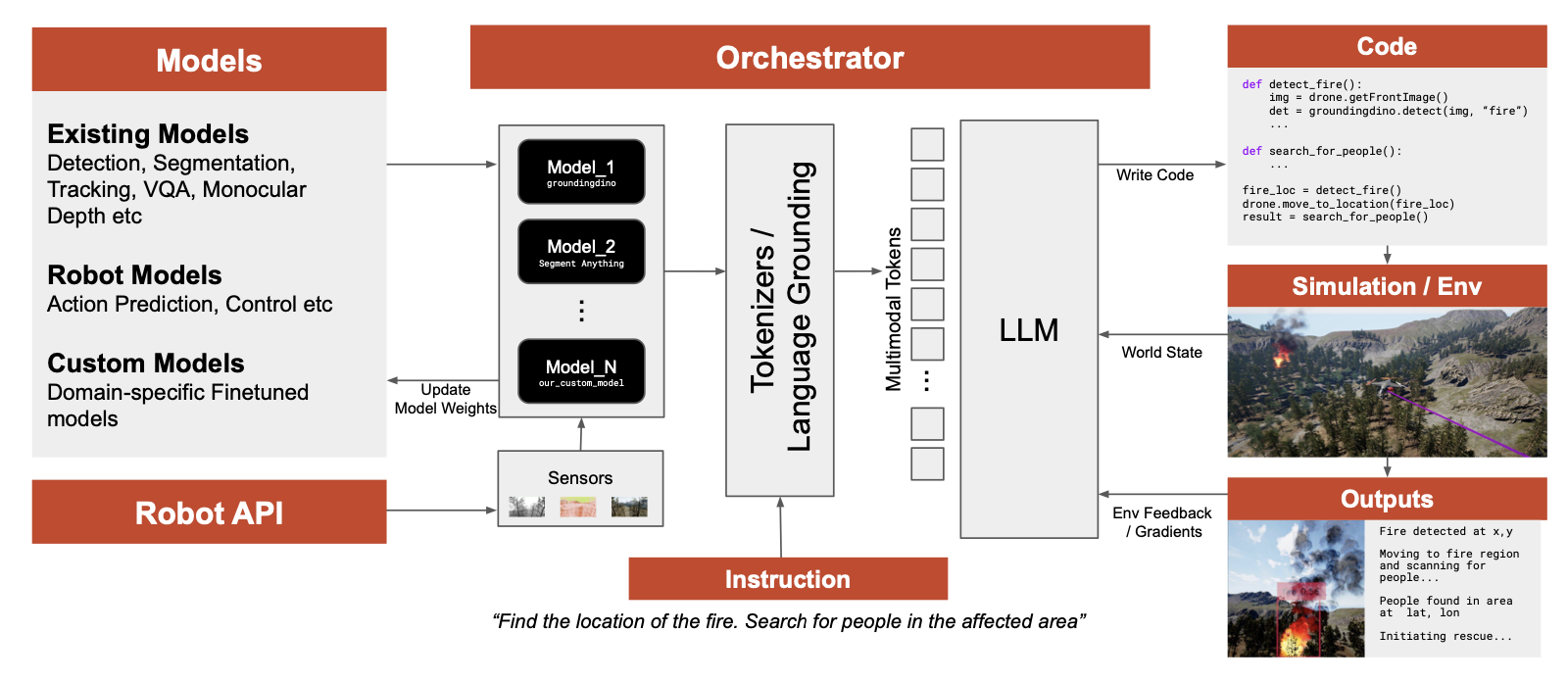
GRID combines the abilities of several state of the art foundation models, and allows them to be orchestrated by language models. The LLM layer is responsible for generates code that embeds the models, and also for refining and improving it through simulation or user feedback.
Large language models are known to be powerful orchestrators, and GRID couples them with state-of-the-art multimodal foundation models. By harnessing the multi-task, multi-domain expertise of foundation models and the code generation capabilities of LLMs, GRID can ingest entire sensor/control APIs of any robot, and for a given task, generate code that goes from sensor -> perception -> reasoning -> control commands.
Central to GRID is a foundation mosaic: a collection of models for computer vision, localization, planning, safety, etc. GRID builds upon several existing state-of-the-art models that can perform object detection, segmentation, VQA, visual odometer, among many more – invoking and chaining them together as needed. GRID also contains a multi-agent LLM architecture which processes user tasks to generate solution plans and deployable code. The LLMs communicate with each other for plan/code improvement, or handling user feedback, resulting in a rich interaction layer that ensures alignment and safety. GRID can also learn reusable skills which can be stored and retrieved.
Simulation also plays a key role in GRID, both as a source of training data for training or fine-tuning models, as well as being a deployment sandbox. GRID contains a high-fidelity simulator AirGen which can generate virtually infinite multimodal, spatiotemporal data. Rich environmental feedback from the simulation can be leveraged by the LLMs to refine their output code and improve their abilities over time.
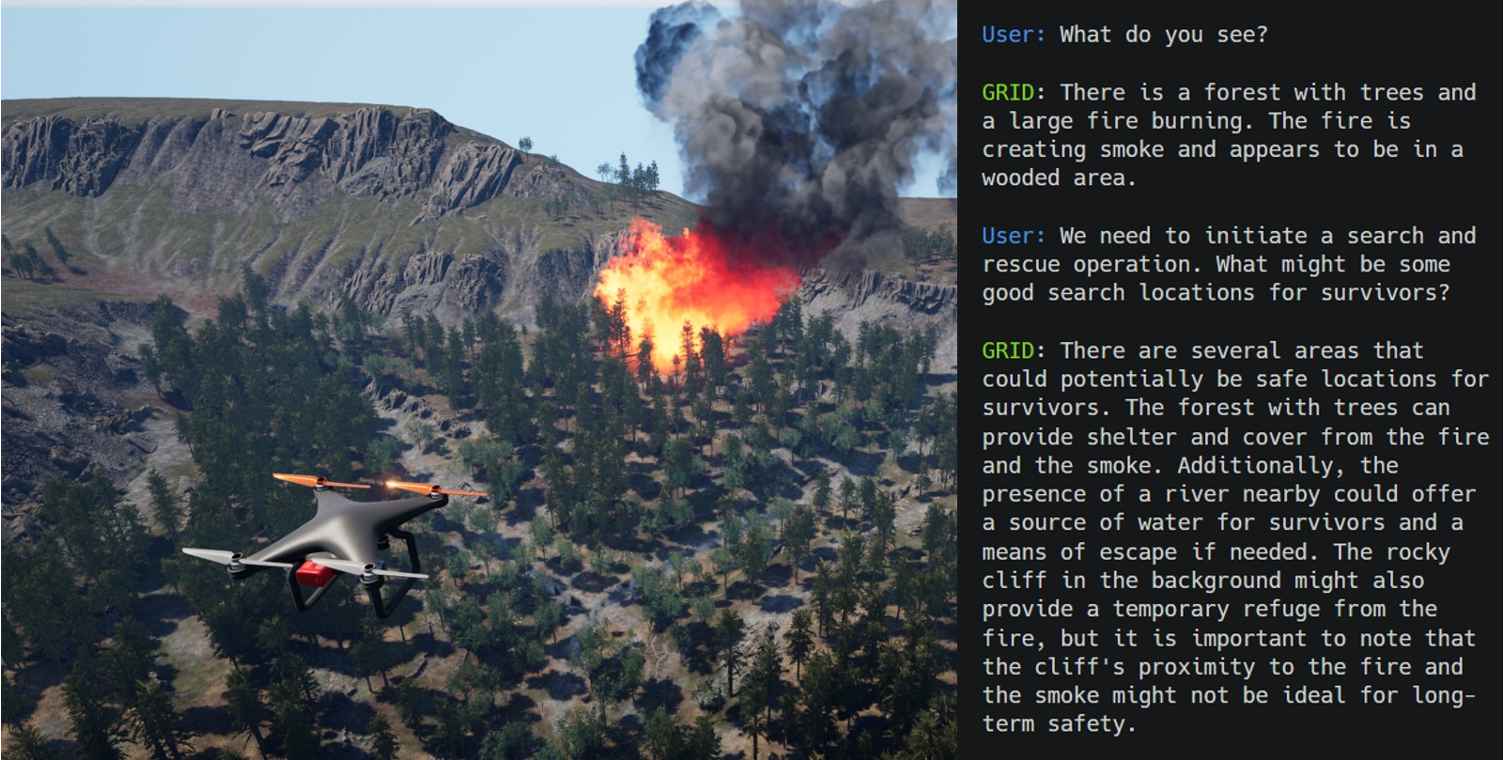
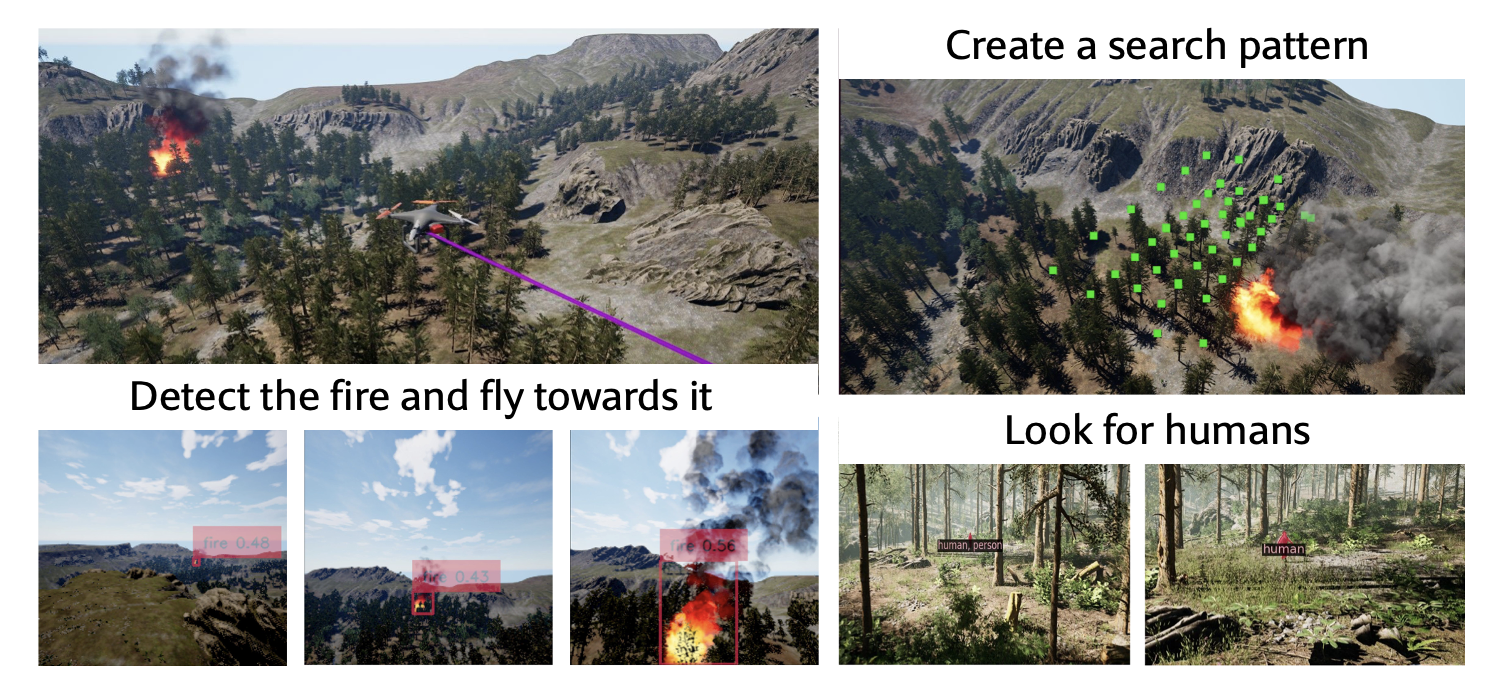
Users can converse with GRID in natural language to solve complex problems. In a simulated forest fire rescue scenario with a drone, GRID produces code that detects the fire, navigates the drone there, plans a search, and flies the drone identifying people in the forest.
Along with enabling this copilot-like behavior for robotics applications, we note that combining LLMs with foundation models ensures effective grounding and reasoning. When asked to detect a safe landing spot for a drone, GRID answers it by internally calling a VQA model, segmenting the pertinent areas, and isolating a flat region using an RGB->depth model. Similarly, GRID understands complex constructs such as a metric-semantic map. When asked to build a metric-semantic map of a scene, GRID correctly combines the abilities of an open segmentation model and an RGB to depth model, and use this answer answer object related queries.

Foundation models also enable significant zero-shot capabilities. We implement a vision based landing module for a drone in GRID using an object detector, a point tracker, and an RGB to depth model – which is robust to adverse weather conditions and low light out of the box. We note here that the interested users can access the models inside GRID directly without going through the LLM layer.
Safety is of paramount importance in robotics, and current approaches for safety often fail to generalize as they rely on complex constraints that are specific to robot platform or task. Robots need an uncompromising notion of safety that is beyond a specific form factor or environment, and we note that foundation models have the potential to provide a robust layer of safety out of the box. As an example, one of the models we use within GRID uses the optical expansion principle (i.e., objects that are getting closer will also be bigger) to compute “time to collision” directly from RGB images. This enables safe navigation in a variety of environments. Simulation feedback can also help refine the code generation of LLMs and align them in order to result in safer policies.

Finally, GRID integrates machine learning models with robotics primitives. GRID can solve an autonomous inspection problem by importing a mesh into simulation (this can be a ground truth mesh such as a CAD model, or a mesh created using generative techniques such as NeRF), and then using depth, segmentation and surface normals along with optimal planning to compute a scanning trajectory. This trajectory can then be executed in real life. GRID can perform vision-based landing, a complex perception action loop completely zero-shot and in a way that is robust.
A tight loop between simulation, foundation models, and robotics primitives enables rapid deployment of applications such as structural inspection.
Through GRID, we want to unite the ML and robotics worlds, and lower the barrier to entry into robotics by making foundation models and simulation accessible to any robotics developer/researcher. Our platform is in alpha preview, and is continuously evolving with new features and updates. GRID is free and unrestricted for academic use. Instructions on how to set up and use our platform, as well as details on the current set of foundation models available in GRID can all be found at our documentation site.
Stay tuned for more updates!